
Marktgröße und Marktanteil im Bereich Versicherungsbetrugserkennung
�Ѳ������ü��������������
| Studienzeitraum | 2020 - 2031 |
|---|---|
| Marktgröße (2026) | 8.52 Milliarden US-Dollar |
| Marktgröße (2031) | 20.22 Milliarden US-Dollar |
| Wachstumsrate (2026 - 2031) | 18.87% CAGR |
| Schnellstwachsender Markt | Asien-Pazifik |
| Größter Markt | Nordamerika |
| Marktkonzentration | Mittel |
Hauptakteure
*Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert Bild © ����������. Wiederverwendung erfordert Namensnennung gemäß CC BY 4.0. |
|
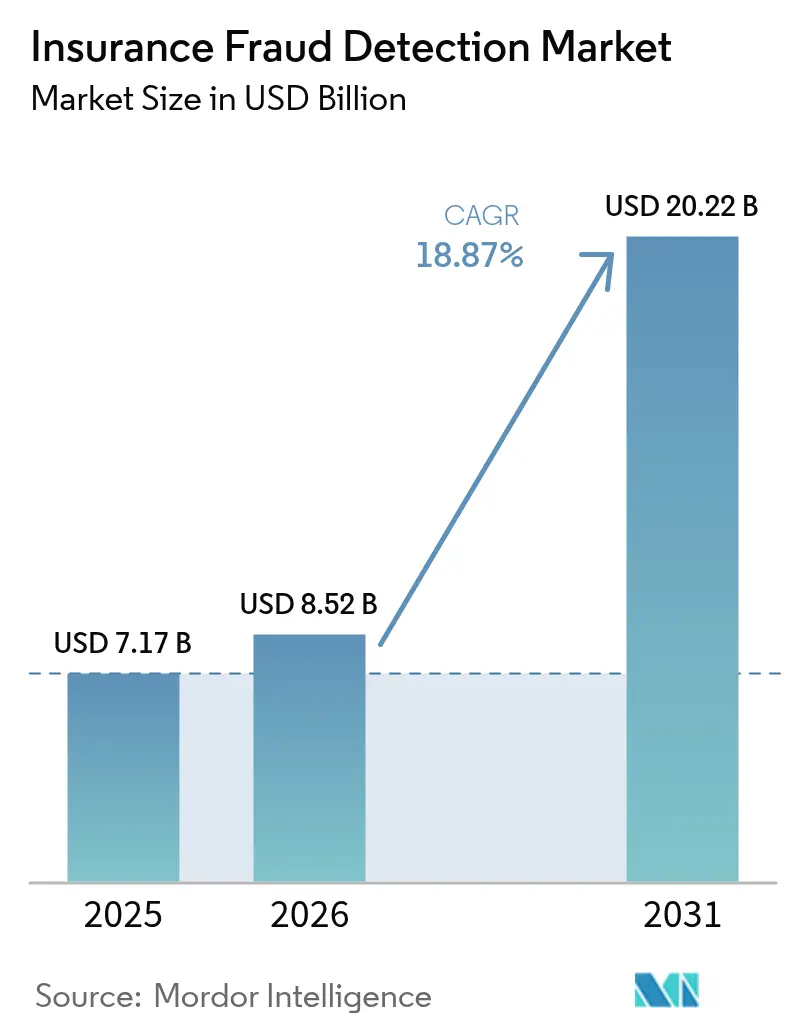
Marktanalyse zur Versicherungsbetrugserkennung von ����������
Die Marktgröße für Versicherungsbetrugserkennung wird voraussichtlich im Jahr 2025 USD 7,17 Milliarden, im Jahr 2026 USD 8,52 Milliarden betragen und bis 2031 USD 20,22 Milliarden erreichen, mit einer CAGR von 18,87 % von 2026 bis 2031. Gestiegene Schadenvolumina, zunehmender Kostendruck und die Forderung nach Echtzeit-Schadenverhütung verlagern Budgets hin zu multimodaler Analytik und einheitlichen Governance-Rahmenwerken. Versicherer, die künstliche Intelligenz in Schadens- und Zeichnungsabläufe einbetten, verkürzen Ermittlungszyklen, senken Falsch-Positiv-Raten und verbessern die Kundenbindung. Technologieanbieter reagieren mit der Veröffentlichung vorintegrierter Konnektoren für Telematik, das Internet der Dinge und Drittanbieter-Datenfeeds, während Beratungsunternehmen laufende Modellvalidierung und Compliance-Prüfungen monetarisieren. Kapitalzuflüsse in Insurtech-Unternehmen signalisieren stetige Innovation, doch regulatorische Vorgaben zur algorithmischen Rechenschaftspflicht erzwingen Transparenzinvestitionen, die Plattformen mit integrierten Prüfpfaden begünstigen.
Wichtigste Erkenntnisse des Berichts
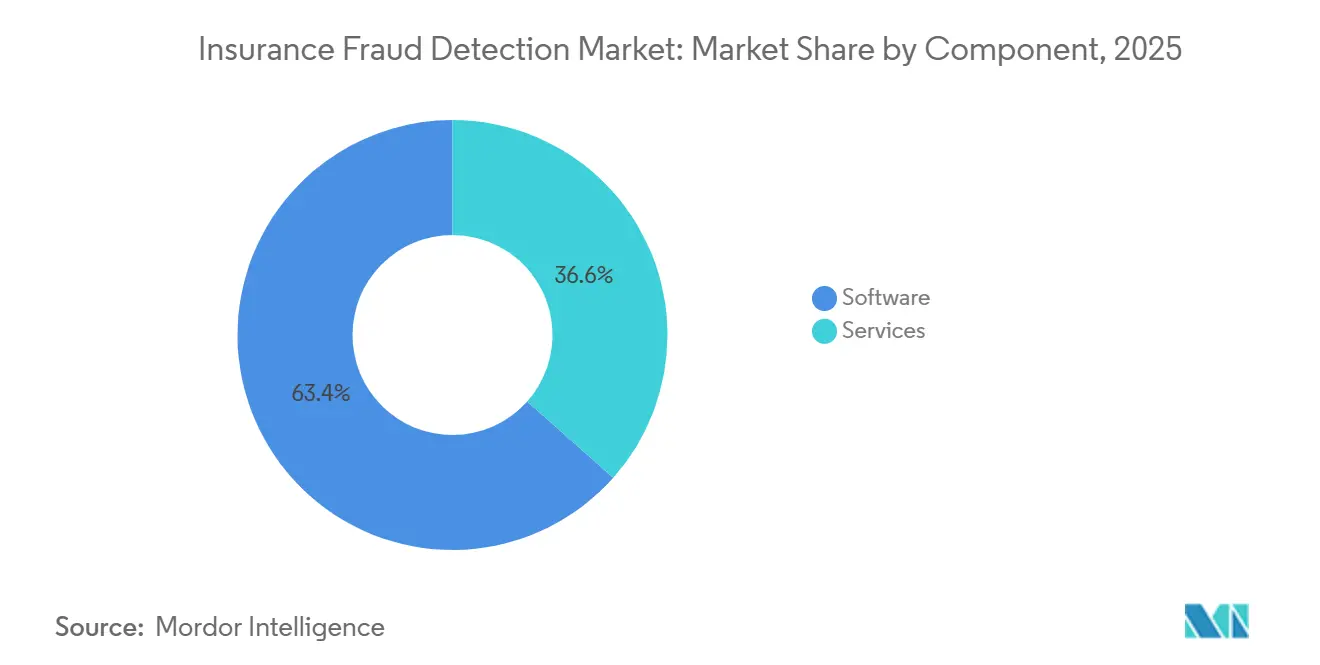
- Nach Komponente entfiel im Jahr 2025 ein Anteil von 63,44 % des Umsatzes im Markt für Versicherungsbetrugserkennung auf Software; Dienstleistungen wachsen bis 2031 mit einer CAGR von 19,07 %.
- Nach Bereitstellungsmodus hielten cloudbasierte Lösungen im Jahr 2025 einen Marktanteil von 58,46 % im Markt für Versicherungsbetrugserkennung, während hybride Architekturen bis 2031 voraussichtlich mit einer CAGR von 19,34 % wachsen werden.
- Nach Unternehmensgröße entfielen im Jahr 2025 69,71 % der Ausgaben auf �Ұ���ß�ܲԳٱ���Ա���; kleine und mittlere Unternehmen werden bis 2031 voraussichtlich mit einer CAGR von 19,11 % wachsen.
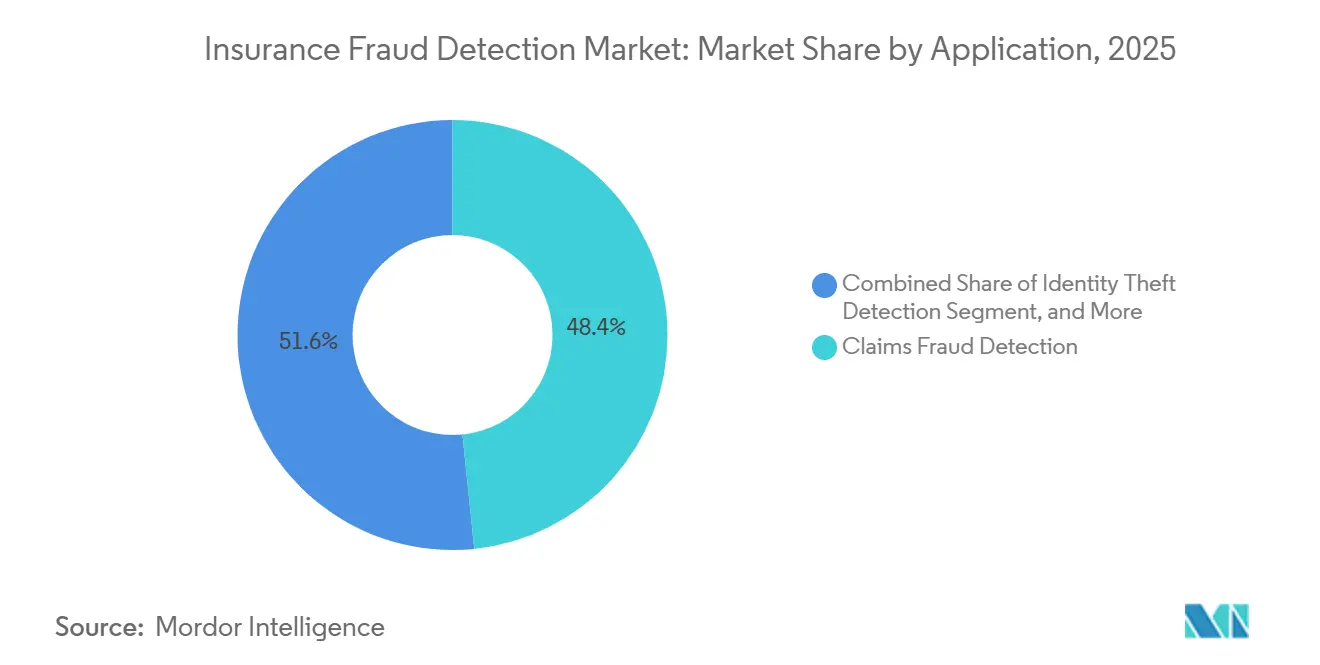
- Nach Anwendung führte die Erkennung von Anspruchsbetrug mit einem Anteil von 48,39 % im Markt für Versicherungsbetrugserkennung im Jahr 2025, während die Erkennung von Identitätsdiebstahl bis 2031 voraussichtlich mit einer CAGR von 19,82 % wachsen wird.
- Nach Endnutzer entfielen 47,93 % des Umsatzes im Jahr 2025 auf die Sach- und Haftpflichtversicherung; die Krankenversicherung wird bis 2031 voraussichtlich mit einer CAGR von 19,67 % wachsen.
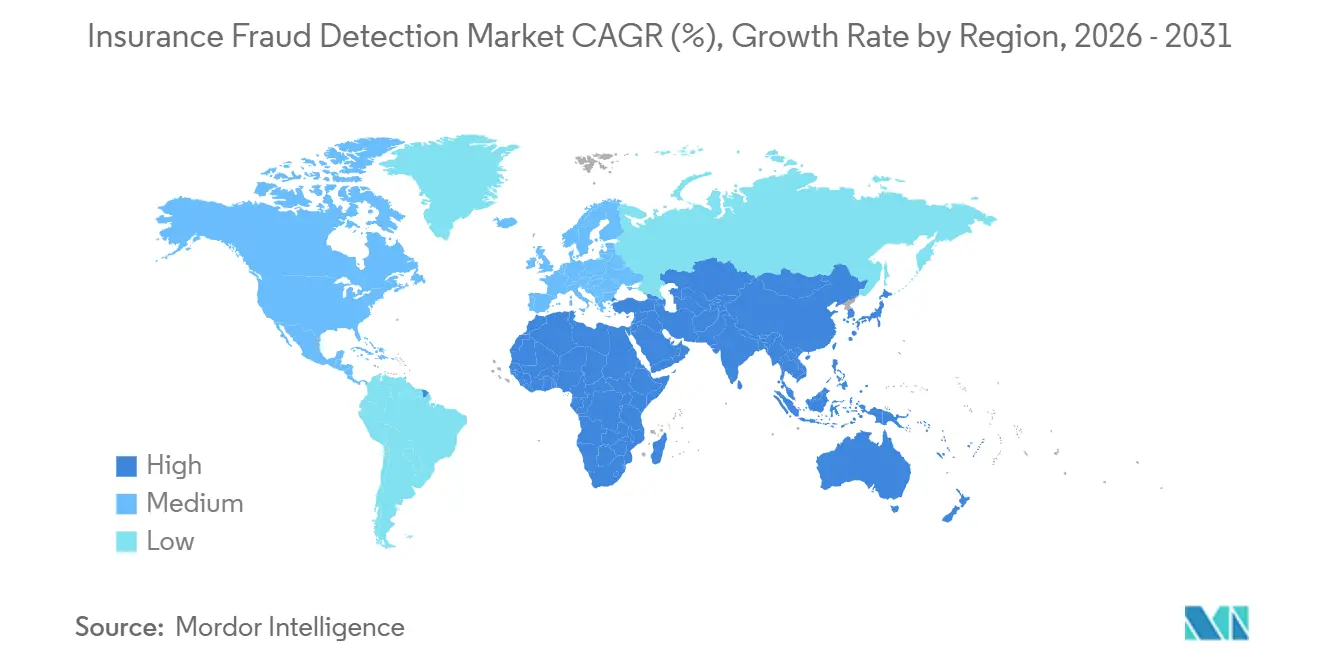
- Nach Geografie hielt Nordamerika im Jahr 2025 einen Anteil von 39,62 % im Markt für Versicherungsbetrugserkennung; der asiatisch-pazifische Raum verzeichnet mit 19,89 % das stärkste Wachstum im Zeitraum 2026–2031.
Hinweis: Die Marktgrößen- und Prognosezahlen in diesem Bericht werden mithilfe des proprietären Schätzrahmens von ���������� erstellt und mit den neuesten verfügbaren Daten und Erkenntnissen bis 2026 aktualisiert.
Globale Trends und Erkenntnisse im Markt für Versicherungsbetrugserkennung
Analyse der Treiberwirkung*
| Treiber | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Zunehmendes Volumen digitaler Schadendaten | +4.2% | Global, mit frühen Gewinnen in Nordamerika, Europa und städtischen Zentren des asiatisch-pazifischen Raums | Mittelfristig (2–4 Jahre) |
| Wachsende Nutzung von Predictive Analytics und künstlicher Intelligenz | +5.1% | Global, konzentriert in Nordamerika, Westeuropa und entwickelten Märkten des asiatisch-pazifischen Raums | Kurzfristig (≤ 2 Jahre) |
| Zunehmender regulatorischer Druck zur Reduzierung von Betrugsverlusten | +3.8% | Kernregion Nordamerika und Europa, Ausstrahlungseffekte auf den asiatisch-pazifischen Raum und den Nahen Osten | Mittelfristig (2–4 Jahre) |
| Zunehmende Raffinesse organisierter Betrugsnetzwerke | +2.9% | Global, mit verstärkten Auswirkungen in Ballungsräumen Nordamerikas, Europas und des asiatisch-pazifischen Raums | Langfristig (≥ 4 Jahre) |
| Verbreitung von Echtzeit-Datenquellen (Telematik, Internet der Dinge) | +3.6% | Kernregion asiatisch-pazifischer Raum, Ausweitung auf Nordamerika und Europa | Mittelfristig (2–4 Jahre) |
| Entstehung von On-Demand-Versicherungsmodellen | +2.1% | Frühe Anwender im asiatisch-pazifischen Raum und Nordamerika, schrittweise Ausbreitung nach Europa und in den Nahen Osten | Langfristig (≥ 4 Jahre) |
| Quelle: ���������� | |||
Zunehmendes Volumen digitaler Schadendaten
Versicherer verarbeiteten im Jahr 2025 mehr als 1,2 Milliarden Mobile-First-Schadenmeldungen, was stapelverarbeitungsorientierte Betrugserkennungssysteme, die auf statischen Geschäftsregeln basieren, überforderte. Foto-, Video- und Geolokalisierungsdateien erfordern Computer-Vision- und Sprachmodelle, die unstrukturierte Eingaben in Sekundenschnelle triagieren können. Frühe Anwender berichteten nach der Einführung multimodaler Analysen von 30 % weniger falsch positiven Ergebnissen, was Ermittlern ermöglichte, sich auf Warnmeldungen mit hohem Schweregrad zu konzentrieren. Das Volumen eingehender Beweise erhöht zudem die Komplexität des Einwilligungsmanagements, da Kunden gemäß Datenschutzgesetzen jederzeit die Erlaubnis zur Nutzung persönlicher Bilder widerrufen können. Anbieter, die elastischen Cloud-Speicher in Kombination mit sicherer Edge-Vorverarbeitung anbieten, gewinnen Versicherungsträger, die mit dem ununterbrochenen Hochladen von Schadenmeldungen Schritt halten müssen, und stärken damit das Wachstum im Markt für Versicherungsbetrugserkennung.
Wachsende Nutzung von Predictive Analytics und künstlicher Intelligenz
Der Einsatz von maschinellem Lernen erreichte im Jahr 2025 62 % der Versicherer weltweit, gegenüber 41 % im Vorjahr, da Versicherungsträger Echtzeit-Betrugsbewertungen zum Zeitpunkt der Angebotsabgabe anstrebten und damit die Innovation im Markt für Versicherungsbetrugserkennung beschleunigten. Plattformen kombinieren nun Telematik-, Kredit- und Social-Media-Daten, um verdächtiges Verhalten zu identifizieren, bevor Policen abgeschlossen werden. Deloitte prognostiziert, dass eine weitverbreitete Einführung von künstlicher Intelligenz dem Sektor bis 2032 Einsparungen von 80 Milliarden bis 160 Milliarden USD ermöglichen könnte. Regulierungsbehörden fordern transparente Modelle, was eine Welle von Investitionen in Erklärbarkeits-Dashboards und Bias-Audits ausgelöst hat, die jeden Eingabe-Parameter dokumentieren.[1]NAIC, "Mustermitteilung zur Nutzung künstlicher Intelligenz durch Versicherer," content.naic.org Anbieter, die eine hohe Erkennungsleistung mit granularer Nachvollziehbarkeit verbinden, gewinnen mehrjährige Unternehmensverträge in Nordamerika und Westeuropa.
Zunehmender regulatorischer Druck zur Reduzierung von Betrugsverlusten
Indiens Richtlinien zur Betrugsüberwachung verpflichten jeden Versicherer ab April 2026, Strafverfolgungsdaten zu integrieren und Verdachtsfälle innerhalb von 30 Tagen zu melden, was neue Technologieausgaben auf dem Subkontinent antreibt. Die US-amerikanische Nationale Vereinigung der Versicherungskommissare veröffentlichte 2025 ein Bulletin, das jährliche Fairness-Prüfungen für jedes Modell vorschreibt, das Schadenergebnisse beeinflusst, und damit Compliance zu einem Thema auf Vorstandsebene macht. Das Gesetz über künstliche Intelligenz der Europäischen Union stuft Betrugserkennung als Hochrisikoanwendungsfall ein und schreibt Konformitätsbewertungen und Vorfallprotokolle vor.[2]Europäische Kommission, „EU-Gesetz über künstliche Intelligenz: Hochrisikosysteme”, ec.europa.eu Konvergierende Vorgaben erhöhen die Kosten der Nichteinhaltung und verlagern Budgets hin zu Plattformen mit integrierten Governance-Modulen. Versicherer, die diese Regeln frühzeitig erfüllen, verbessern das Vertrauen der Regulierungsbehörden und erhalten schnellere Produktgenehmigungen.
Verbreitung von Echtzeit-Datenquellen
Vernetzte Fahrzeuge übertragen nun sekündliche Brems- und Standortdaten, sodass Kfz-Versicherer Unfallschilderungen innerhalb von Minuten validieren können.[3]Verisk Analytics, „ISO ClaimSearch Telematik-Integration”, verisk.com Krankenversicherer nehmen Herzfrequenz- und Aktivitätsdaten von Wearables auf, um vorgetäuschte Berufsunfähigkeitsansprüche aufzudecken, während Sachversicherungslinien intelligente Haussensoren auf Wasser- oder Brandanomalien überwachen. Versicherer im asiatisch-pazifischen Raum führen diesen Wandel an, da hohe Smartphone-Durchdringung und staatliche Telematikanreize die Hürden für die Datenerhebung senken. Microsofts Confidential-Computing-Dienst auf Azure verschlüsselt Daten während der Modellausführung und ermöglicht hybride Arbeitsabläufe, die Datensouveränitätsregeln respektieren. Echtzeit-Datenaufnahme schärft Risikobewertungen, zwingt Versicherer aber auch, in Niedriglatenz-Netzwerke und Edge-Vorverarbeitungsknoten zu investieren.
Analyse der Hemmnisauswirkung*
| Hemmnis | (~) % Auswirkung auf die CAGR-Prognose | Geografische Relevanz | Zeithorizont der Auswirkung |
|---|---|---|---|
| Datenschutz- und Einwilligungsbeschränkungen | -2.7% | Kernregion Europa und Nordamerika, Ausweitung auf den asiatisch-pazifischen Raum und ��ü�岹��������첹 | Kurzfristig (≤ 2 Jahre) |
| Integrationskomplexität mit Legacy-Kernsystemen | -2.3% | Global, mit akuten Herausforderungen in den reifen Märkten Nordamerikas und Europas | Mittelfristig (2–4 Jahre) |
| Hohe Kosten für qualifizierte Data-Science-Fachkräfte | -1.6% | Global, konzentriert in Technologiezentren Nordamerikas, Europas und des asiatisch-pazifischen Raums | Langfristig (≥ 4 Jahre) |
| Bias- und Fairness-Bedenken bei Modellen der künstlichen Intelligenz | -1.9% | Regulatorischer Schwerpunkt in Nordamerika und Europa, Ausstrahlungseffekte auf den asiatisch-pazifischen Raum | Mittelfristig (2–4 Jahre) |
| Quelle: ���������� | |||
Datenschutz- und Einwilligungsbeschränkungen
Die Datenschutz-Grundverordnung der Europäischen Union und der California Consumer Privacy Act erfordern ausdrückliche Einwilligungen, bevor persönliche Daten in Betrugsmodelle einfließen können, was nutzbare Datensätze verkleinert, wenn Versicherungsnehmer die Einwilligung verweigern. Indiens Gesetz zum Schutz digitaler personenbezogener Daten erlaubt Anspruchstellern, eine menschliche Überprüfung automatisierter Entscheidungen zu verlangen, was die ohnehin belasteten Ermittlungsteams zusätzlich beansprucht. Multinationale Versicherer müssen nun regionsspezifische Arbeitsabläufe entwickeln, die den strengsten Standards entsprechen, was Projektzeitpläne und Rechtskosten in die Höhe treibt. Kleinere Versicherer ohne eigene Rechtsabteilung tragen höhere Compliance-Kosten pro Police, was die Einführung Cloud-basierter Analytik verlangsamt. Anbieter, die granulares Einwilligungsmanagement und automatisierte Löschroutinen anbieten, verschaffen sich einen Wettbewerbsvorteil.
Integrationskomplexität mit Legacy-Kernsystemen
Viele Versicherer betreiben noch immer Mainframe-Policenplattformen aus den 1990er Jahren, denen Programmierschnittstellen für die Echtzeit-Bewertung fehlen. Individuelle Middleware-Projekte können 18–24 Monate dauern und einen mittelgroßen Versicherer bis zu USD 15 Millionen kosten, was die Rendite von Investitionen in die Betrugserkennung verzögert. Hybride Architekturen versuchen, diese Lücke zu schließen, indem sie tokenisierte Merkmalssätze an Cloud-Modelle senden und Ergebnisse wieder On-Premise zurückleiten, doch Versionsabweichungen zwischen Regelmaschinen und Modellen des maschinellen Lernens können Latenz verursachen. Guidewire, Duck Creek und Majesco liefern nun vorgefertigte Konnektoren, doch die Akzeptanz bleibt gering, wo Vorstandsgenehmigungen für Kernsystemänderungen erforderlich sind. Versicherer, die Legacy-Systeme frühzeitig modernisieren, ermöglichen schnellere Schadensentscheidungen und niedrigere Gesamtbetriebskosten.
*Unsere Prognosen behandeln die Auswirkungen von Treibern und Einschränkungen als richtungsweisend und nicht additiv. Die Wirkungsprognosen berücksichtigen Basiswachstum, Mischungseffekte und Wechselwirkungen zwischen Variablen.
Segmentanalyse
Nach Komponente: Dienstleistungen wachsen auf der Grundlage der Governance-Nachfrage
Software hielt im Jahr 2025 63,44 % des Komponentenumsatzes, doch Dienstleistungen wachsen mit einer CAGR von 19,07 %, was ihren Anteil am Markt für Versicherungsbetrugserkennung bis 2031 steigern wird. Der Anstieg spiegelt den wachsenden Bedarf an Bias-Prüfungen, Modell-Nachtraining und regulierungskonformer Dokumentation wider, die viele Versicherer lieber auslagern als intern aufbauen. Dienstleistungsanbieter bündeln nun Implementierungsberatung mit wiederkehrenden Managed-Detection-Abonnements und wandeln einmalige Lizenzkäufer in langfristige Umsatzquellen um. Da der Marktanteil der Dienstleistungen im Markt für Versicherungsbetrugserkennung steigt, reagieren Softwareanbieter, indem sie Prüfpfade und Fairness-Dashboards direkt in Kernplattformen einbetten, um die Kundenbindung zu verteidigen.
Der Wandel begünstigt Beratungsunternehmen, die Expertise über mehrere Governance-Regime hinweg aufrechterhalten, darunter das Bulletin der Nationalen Vereinigung der Versicherungskommissare in den Vereinigten Staaten und das Gesetz über künstliche Intelligenz der Europäischen Union. Sie bieten risikobasierte Preisgestaltung an, die monatliche Gebühren mit eingesparten Betrugsverlusten verknüpft – ein Ansatz, der bei Finanzteams unter Margendruck Anklang findet. Oracle, SAP und IBM haben dienstleistungsintensive Abonnementtarife eingeführt, die Plattformzugang mit kontinuierlicher Überwachung verbinden und Beschaffungszyklen für mittelgroße Versicherer ohne eigene Data Scientists verkürzen. Über den Prognosehorizont hinaus wird die Nachfrage nach nachweisbereiten Compliance-Artefakten das Dienstleistungswachstum über das Softwarewachstum hinaus halten, auch wenn Low-Code-Tools den anfänglichen Implementierungsaufwand reduzieren.


Nach Bereitstellungsmodus: Hybridmodelle verbinden Cloud-Wirtschaftlichkeit und Datenkontrolle
Cloud-Implementierungen erzielten im Jahr 2025 einen Umsatzanteil von 58,46 %, doch hybride Bereitstellungen verzeichnen mit 19,34 % die schnellste CAGR und sind damit positioniert, vor 2031 Marktanteile im Markt für Versicherungsbetrugserkennung zu gewinnen. Hybrid ermöglicht es Versicherern, sensible Schadendaten On-Premise zu verarbeiten, während tokenisierte Merkmale an Cloud-Modelle gesendet werden – eine Architektur, die Datensouveränitätsregeln in Ländern wie Deutschland und Japan erfüllt. Confidential-Computing-Enklaven auf Microsoft Azure und ähnlichen Plattformen verschlüsseln Daten während der Verarbeitung und machen hybride Umgebungen für risikoscheue Compliance-Teams akzeptabel. Edge-Gateways reduzieren die Latenz weiter, indem sie Bilder komprimieren und betrugsrelevante Merkmale nahe an der Datenquelle extrahieren und so eine Echtzeit-Bewertung auch bei geringer Weitverkehrsbandbreite gewährleisten.
Die Komplexität bleibt bestehen, da Modellversionen in der Cloud mit On-Premise-Regelmaschinen synchronisiert bleiben müssen, um Bewertungsabweichungen zu vermeiden. Anbieter bieten einheitliche Orchestrierungsschichten an, die Rollout und Rollback über Ebenen hinweg automatisieren und Versicherern ermöglichen, agile Release-Zyklen einzuführen, ohne Prüfkontrollen zu verletzen. Investitionen in souveräne Clouds regionaler Hyperscaler senken jurisdiktionelle Hürden und bringen konservativen Märkten zusätzliche Rechenoptionen. Infolgedessen wird die Marktgröße für Versicherungsbetrugserkennung, die mit hybriden Projekten verbunden ist, weiter beschleunigen, insbesondere bei nationalen Versicherern, die gemischte Mainframe- und Microservice-Bestände betreiben.
Nach Unternehmensgröße: Kleine und mittlere Unternehmen setzen auf Abonnementflexibilität
�Ұ���ß�ܲԳٱ���Ա��� machten im Jahr 2025 69,71 % der Ausgaben aus, doch kleine und mittlere Unternehmen verzeichneten eine CAGR von 19,11 % und steigern damit stetig ihren Anteil am Markt für Versicherungsbetrugserkennung. Günstige Software-as-a-Service-Pakete geben regionalen Versicherern und Spezialzeichnern sofortigen Zugang zu denselben multimodalen Analysen, die erstklassige Versicherer einsetzen. Nutzungsbasierte Preisgestaltung minimiert den Kapitaleinsatz, während Managed-Service-Optionen den Bedarf an eigenen Data-Science-Fachkräften entfallen lassen. Eingebettete Versicherungsplattformen, die bei Banken und Mobilitätsbetreibern beliebt sind, senken technische Hürden weiter, indem sie Betrugsbewertung als integrierte Funktion einschließen.
Trotz des Schwungs kann die Integration ins Stocken geraten, wenn Policenverwaltungssysteme offene Standards vermissen lassen. Anbieter begegnen dem mit Programmierschnittstellen, die ACORD-Schemata entsprechen und kleineren Versicherern die Anbindung ohne individuelle Middleware ermöglichen. Viele fügen auch Self-Service-Konfigurationsassistenten hinzu, mit denen nicht-technisches Personal Risikoschwellenwerte anpassen kann, was die Inbetriebnahme beschleunigt. Langfristig werden wertbasierte Verträge, die Abonnementgebühren an bestätigte Betrugsrückgewinnungen knüpfen, die Akzeptanz stärken und sicherstellen, dass der Marktanteil kleiner und mittlerer Unternehmen im Markt für Versicherungsbetrugserkennung schneller wächst als die Gesamtmarktexpansion.
Nach Anwendung: �����Գپ���ä�ٲ��徱������ٲ����������ԲԳܲԲ� übertrifft traditionelle Schadenskontrollen
Die Schadensbetrugserkennnung machte im Jahr 2025 48,39 % des Anwendungsumsatzes aus, doch die �����Գپ���ä�ٲ��徱������ٲ����������ԲԳܲԲ� wächst mit einer CAGR von 19,82 % und erweitert ihren Marktanteil im Bereich Versicherungsbetrugserkennung von Jahr zu Jahr. Synthetische Personas nutzen nun schnelles digitales Onboarding, um mehrere Policen abzuschließen und koordinierte Schäden einzureichen, was Versicherer unter Druck setzt, Identitäten vorgelagert zu verifizieren. Neue Modelle verknüpfen öffentliche Register, Gerätefingerabdrücke und Verhaltensbiometrie, um Anomalien zu erkennen, bevor Policen abgeschlossen werden. Im Schadensstadium vergleichen Sprachverarbeitungsmaschinen Schilderungen mit früheren Einreichungen, um recycelte Handlungsstränge zu kennzeichnen.
Einheitliche Plattformen, die Angebots-, Schadens- und Zahlungstransaktionen in einer einzigen Graphdatenbank analysieren, decken organisierte Netzwerke auf, die zwischen Betrugsvektoren wechseln. Frühe Anwender berichten von zweistelligen Verbesserungen der Erkennungsleistung, wenn sie isolierte Tools aufgeben und zu Lebenszyklus-Analytik wechseln. Anbieter-Roadmaps umfassen nun Zero-Trust-Identitätsgraphen und Dokumentenfälschungssensoren, die Artefakte auf Pixelebene lesen und so ein neues Differenzierungsniveau schaffen. Da die digitale Distribution die Zeichnungszyklen weiter verkürzt, wird die Marktgröße für Versicherungsbetrugserkennung, die mit identitätszentrierten Modulen verbunden ist, schneller wachsen als jedes andere Anwendungscluster.

Nach Endnutzer: Krankenversicherung führt zukünftige Ausgabenkurven an
Sach- und Haftpflichtversicherungslinien hielten im Jahr 2025 47,93 % der Ausgaben, doch Krankenversicherer verzeichneten eine CAGR von 19,67 % und steigern damit rasch ihren Beitrag zum Markt für Versicherungsbetrugserkennung. Nationale Schadenaustauschsysteme, wie die All-Payer Claims Database in den Vereinigten Staaten und Indiens National Health Claims Exchange, aggregieren Abrechnungsdaten über Kostenträger hinweg und erleichtern die Identifizierung von Doppelberechnungen und Entbündelungsschemata. Maschinen der künstlichen Intelligenz vergleichen nun Anbieterrechnungen mit Peer-Kohorten und evidenzbasierten Behandlungspfaden und kennzeichnen Ausreißer in Sekunden.
Das Wachstum resultiert auch aus dem Anstieg der Telemedizin, bei der virtuelle Konsultationen neue Verifizierungsherausforderungen hinsichtlich Patientenidentität und Dienstauthentizität aufwerfen. Generative Modelle fassen umfangreiche elektronische Krankenakten zusammen und beschleunigen die Überprüfung durch Ermittler, ohne persönliche Daten menschlichen Kodierern preiszugeben. Lebensversicherer setzen ähnliche Ansätze ein, um Angaben von Antragstellern zu bestätigen, während Rückversicherer gemeinsame Ledger erproben, die Wiederholungstäter über Zedentengrenzen hinweg auf Sperrlisten setzen. Zusammen erheben diese Verschiebungen Krankenversicherer zum schnellsten Beitragenden zu inkrementellen Umsätzen und steigern ihren Marktanteil im Bereich Versicherungsbetrugserkennung über den Prognosehorizont hinaus.
Geografische Analyse
Nordamerika hielt im Jahr 2025 39,62 % des Marktanteils im Bereich Versicherungsbetrugserkennung und unterstreicht damit seinen Status als größter regionaler Käufer fortschrittlicher Analyseplattformen. Regulatorische Katalysatoren, wie das Bulletin der Nationalen Vereinigung der Versicherungskommissare und Colorados Gesetz über künstliche Intelligenz, verpflichten Versicherer zu jährlichen Fairness-Prüfungen und lenken Technologiebudgets in die Entwicklung von Erklärbarkeits-Dashboards. Versicherer in den Vereinigten Staaten balancieren proprietäre Entwicklungen mit Software-as-a-Service-Abonnements, während Kanadas Flickenteppich provinzieller Regeln grenzüberschreitende Plattform-Rollouts erschwert und Implementierungszyklen verlängert. Mexikos geringe Versicherungsdurchdringung begrenzt die Ausgaben, doch grenzüberschreitende Kfz-Betrugspressionen treiben die Einführung telematikgestützter Verifizierungstools voran, die Unfallstandorte validieren.
Der asiatisch-pazifische Raum verzeichnet mit 19,89 % die schnellste regionale CAGR und ist damit positioniert, den Markt für Versicherungsbetrugserkennung bis 2031 auf eine größere Größe zu treiben als jede andere Geografie. Indiens Vorgabe, die jeden Versicherer verpflichtet, bis April 2026 ein integriertes Betrugsüberwachungsrahmenwerk einzusetzen, erschließt Investitionen in Höhe von Hunderten von Millionen Dollar. Chinas digitale Versicherer bildeten 2025 eine Big-Data-Allianz, die anonymisierte Muster teilt, doppelte Ermittlungen reduziert und Sperrlisten-Aktualisierungen beschleunigt. Japan migriert von manuellen Prüfungen zur Anomaliebewertung, nachdem eine Untersuchung im Jahr 2025 systematische Lebensversicherungsfalschdarstellungen aufdeckte und Versicherer veranlasste, Drittanbieter-Validierungsfeeds zu integrieren. ��ü���ǰ���s 15-tägige Betrugsmeldefrist und Hongkongs regulatorische Kohortenprogramme runden einen regionweiten Vorstoß hin zu Echtzeit-Analytik ab.
Europa, der Nahe Osten und Afrika sowie ��ü�岹��������첹 tragen kleinere, aber stetig wachsende Anteile an der globalen Nachfrage bei. Das Gesetz über künstliche Intelligenz der Europäischen Union stuft Betrugserkennung als Hochrisikokategorie ein und schreibt Konformitätsbewertungen vor, die Anbieter mit integrierten Prüfpfaden begünstigen. Britische Leitlinien zu diskriminierenden Ergebnissen weiten die Ausgaben für Bias-Minderung aus, während Deutschlands Datensouveränitätsregeln viele Bereitstellungen in privaten Clouds halten. Die Vereinigten Arabischen Emirate fördern Pilotprojekte, verfügen jedoch über keine einheitlichen Datenschutzcodes, was Versicherer dazu veranlasst, modulare Plattformen einzuführen, die sie schnell lokalisieren können. Brasiliens Leitlinien, die Produktgenehmigungen mit Betrugsvorbeugungsfähigkeiten verknüpfen, drängen Versicherer zu modernen Tools, obwohl die Gesamtausgaben durch geringe Versicherungsdichte und makroökonomische Volatilität begrenzt bleiben.

Wettbewerbslandschaft
Der Markt für Versicherungsbetrugserkennung bleibt mäßig fragmentiert, wobei kein Anbieter einen globalen Umsatzanteil von 15 % überschreitet, was sowohl für etablierte Analysegiganten als auch für agile Insurtech-Herausforderer fortlaufende Chancen schafft. SAS Institute, IBM und Fair Isaac Corporation nutzen jahrzehntelange versicherungsmathematische Daten und fest verankerte Policenverwaltungsintegrationen, um Betrugsmodule innerhalb umfassenderer Risikosuiten zu verkaufen. Ihre Größe unterstützt Großvolumen-Benchmarks und globale Support-Desks, die erstklassige Versicherer mit komplexen Multi-Sparten-Portfolios ansprechen.
Spezialisierte Neueinsteiger, darunter Shift Technology, Friss und DataRobot, gewinnen Aufträge durch verbrauchsbasierte Preisgestaltung, schnelle Cloud-Bereitstellung und Modelltransparenz, die neueren Vorgaben zur algorithmischen Rechenschaftspflicht genügen. Die Series-D-Finanzierung im Juli 2024 gab Shift Technology ein Kriegsbudget von USD 100 Millionen, um in Japan und Südostasien zu expandieren, wo Versicherer schlüsselfertige Konnektoren für Telematikgeräte und Sensoren des Internets der Dinge schätzen. Friss bietet vorgefertigte Regelwerke, die auf regionale Betrugstypologien abgestimmt sind, und hilft mittelgroßen Versicherern, zweistellige Verbesserungen ohne langwierige Data-Science-Projekte zu erzielen.
Technologiekonzerne wie Microsoft, Oracle und SAP integrieren Betrugsanalytik in umfassendere Plattformen zur Bekämpfung von Finanzkriminalität und verkürzen Beschaffungszyklen für Versicherer, die bereits auf diesen Clouds standardisiert sind. Microsofts Confidential-Computing-Funktionen auf Azure ermöglichen es Versicherern, verschlüsselte Schadendaten zu verarbeiten, was risikoscheue Käufer zu diesem Stack hinzieht. Oracle und SAP bündeln kontinuierliche Überwachungsdienste und wandeln Lizenzgeschäfte in wiederkehrende Abonnements um, die Gebühren an eingesparte Betrugsgewinne knüpfen. Eine Konsolidierung zeichnet sich ab, da Versicherer einheitliche Multi-Sparten-Erkennungsmaschinen gegenüber Einzellösungen bevorzugen, und Anbieter mit integrierten Governance-Dashboards und Lebenszyklus-Analytik sind positioniert, die nächste Welle von Marktanteilsgewinnen zu erfassen.
Marktführer im Bereich Versicherungsbetrugserkennung
-
SAS Institute Inc.
-
IBM Corporation
-
Fair Isaac Corporation
-
BAE Systems plc
-
Experian plc
- *Haftungsausschluss: Hauptakteure in keiner bestimmten Reihenfolge sortiert

Jüngste Branchenentwicklungen
- Januar 2026: Microsoft Azure erweiterte die Confidential-Computing-Unterstützung auf Versicherungsworkloads und ermöglicht es Versicherern, Betrugsmodelle auf verschlüsselten Schäden in sicheren Enklaven auszuführen.
- Dezember 2025: Indiens Versicherungsregulierungs- und Entwicklungsbehörde finalisierte Betrugsüberwachungsrichtlinien, die bis April 2026 dedizierte Erkennungseinheiten vorschreiben.
- Oktober 2025: Oracle veröffentlichte eine integrierte Suite für Finanzkriminalität und Compliance, die bei Pilotversicherern Falsch-Positiv-Ergebnisse um 35 % reduzierte.
- September 2025: Hongkongs Versicherungsbehörde startete ein Kohortenprogramm für künstliche Intelligenz mit sieben Versicherern, um Betrugsmodelle und Transparenzstandards zu testen.


Berichtsumfang des globalen Marktes für Versicherungsbetrugserkennung
Der Markt für Versicherungsbetrugserkennung ist segmentiert nach Komponente (Software und Dienstleistungen), Bereitstellungsmodus (On-Premise, Cloud-basiert, Hybrid), Unternehmensgröße (�Ұ���ß�ܲԳٱ���Ա��� sowie kleine und mittlere Unternehmen), Anwendung (Schadensbetrugserkennnung, Zeichnungsbetrug, �����Գپ���ä�ٲ��徱������ٲ����������ԲԳܲԲ�, Zahlungs- und Abrechnungsbetrug, sonstige Anwendungen), Endnutzer (Sach- und Haftpflichtversicherung, Lebensversicherung, Krankenversicherung, sonstige Endnutzer) sowie Geografie (Nordamerika, ��ü�岹��������첹, Europa, asiatisch-pazifischer Raum, Naher Osten und Afrika). Die Marktprognosen werden in Wertangaben (USD) bereitgestellt.
| Software |
| Dienstleistungen |
| On-Premise |
| Cloud-basiert |
| Hybrid |
| �Ұ���ß�ܲԳٱ���Ա��� |
| Kleine und mittlere Unternehmen |
| Schadensbetrugserkennnung |
| Zeichnungsbetrug |
| �����Գپ���ä�ٲ��徱������ٲ����������ԲԳܲԲ� |
| Zahlungs- und Abrechnungsbetrug |
| Sonstige Anwendungen |
| Sach- und Haftpflichtversicherung |
| Lebensversicherung |
| Krankenversicherung |
| Sonstige Endnutzer |
| Nordamerika | Vereinigte Staaten | |
| Kanada | ||
| Mexiko | ||
| ��ü�岹��������첹 | Brasilien | |
| Argentinien | ||
| Übriges ��ü�岹��������첹 | ||
| Europa | Vereinigtes Königreich | |
| Deutschland | ||
| Frankreich | ||
| Italien | ||
| Übriges Europa | ||
| Asiatisch-pazifischer Raum | China | |
| Japan | ||
| Indien | ||
| ��ü���ǰ��� | ||
| Übriger asiatisch-pazifischer Raum | ||
| Naher Osten und Afrika | Naher Osten | Vereinigte Arabische Emirate |
| Saudi-Arabien | ||
| Übriger Naher Osten | ||
| Afrika | ��ü�岹�ڰ����첹 | |
| Ä�����ٱ�� | ||
| Übriges Afrika | ||
| Nach Komponente | Software | ||
| Dienstleistungen | |||
| Nach Bereitstellungsmodus | On-Premise | ||
| Cloud-basiert | |||
| Hybrid | |||
| Nach Unternehmensgröße | �Ұ���ß�ܲԳٱ���Ա��� | ||
| Kleine und mittlere Unternehmen | |||
| Nach Anwendung | Schadensbetrugserkennnung | ||
| Zeichnungsbetrug | |||
| �����Գپ���ä�ٲ��徱������ٲ����������ԲԳܲԲ� | |||
| Zahlungs- und Abrechnungsbetrug | |||
| Sonstige Anwendungen | |||
| Nach Endnutzer | Sach- und Haftpflichtversicherung | ||
| Lebensversicherung | |||
| Krankenversicherung | |||
| Sonstige Endnutzer | |||
| Nach Geografie | Nordamerika | Vereinigte Staaten | |
| Kanada | |||
| Mexiko | |||
| ��ü�岹��������첹 | Brasilien | ||
| Argentinien | |||
| Übriges ��ü�岹��������첹 | |||
| Europa | Vereinigtes Königreich | ||
| Deutschland | |||
| Frankreich | |||
| Italien | |||
| Übriges Europa | |||
| Asiatisch-pazifischer Raum | China | ||
| Japan | |||
| Indien | |||
| ��ü���ǰ��� | |||
| Übriger asiatisch-pazifischer Raum | |||
| Naher Osten und Afrika | Naher Osten | Vereinigte Arabische Emirate | |
| Saudi-Arabien | |||
| Übriger Naher Osten | |||
| Afrika | ��ü�岹�ڰ����첹 | ||
| Ä�����ٱ�� | |||
| Übriges Afrika | |||


Im Bericht beantwortete Schlüsselfragen
Wie groß ist die prognostizierte Marktgröße für Versicherungsbetrugserkennung bis 2031?
Es wird prognostiziert, dass der Markt bis 2031 USD 20,22 Milliarden erreicht und über 2026–2031 mit einer CAGR von 18,87 % wächst.
Welches Bereitstellungsmodell wächst am schnellsten?
Hybride Architekturen wachsen mit einer CAGR von 19,34 %, da Versicherer Cloud-Skalierbarkeit mit Datensouveränitätsanforderungen in Einklang bringen.
Warum gewinnen Dienstleistungen gegenüber Software an Marktanteil?
Versicherer lagern zunehmend Bias-Prüfungen, Modell-Feinabstimmung und regulatorische Dokumentation aus, was eine CAGR von 19,07 % für Dienstleistungen antreibt.
Welche Anwendung wird die höchste Wachstumsrate verzeichnen?
Die �����Գپ���ä�ٲ��徱������ٲ����������ԲԳܲԲ�, angetrieben durch Schemata mit synthetischen Identitäten, wird bis 2031 voraussichtlich mit einer CAGR von 19,82 % wachsen.
Wie beeinflussen Vorschriften die Technologieausgaben?
Vorgaben von Behörden wie der Nationalen Vereinigung der Versicherungskommissare, der Versicherungsregulierungs- und Entwicklungsbehörde Indiens und dem Gesetz über künstliche Intelligenz der Europäischen Union erfordern Erklärbarkeit und Prüfpfade und drängen Versicherer zu Plattformen mit integrierten Governance-Funktionen.
Welche Region verzeichnet die schnellste Marktexpansion?
Der asiatisch-pazifische Raum führt mit einer CAGR von 19,89 % aufgrund neuer Betrugsüberwachungsanforderungen und kooperativer Datenaustauschinitiativen.
Seite zuletzt aktualisiert am:




